Plan VI Final Summary
Sam Habiel, Pharm.D./ OSEHRA/ 7 Aug 2019
This is a post that will summarize all of the changes that we made to VistA in order for VistA to work with languages other the US English. We will also describe some items that we couldn't solve in our timeline. The table of contents should give you a good idea of all the items in the list. At the end of the document, you can find links to all the KIDS builds, docker images, and the Github repos hosting all the changes made to the VistA source code.
Overall Goal of the Project
I personally know how big VistA is; so we tried to focus the project on items that will have wide applicability. That's why we focused on making CPRS usable with other languages; and why we didn't spend as much time in Roll and Scroll applications to do the same.
Topics
VistA must run in UTF-8 Mode
We used GT.M and YottaDB for the database. We needed to configure VistA to run in UTF-8 mode. To do that, you need to do the following:
- libicu needs to be installed; and perhaps depending on your distribution, libicu-dev.
$gtmroutinesneeds to point to routines in$gtm_dist/utf8(shared object for x64).- Set
LC_ALLandLC_LANGto the correct UTF-8 locale. gtm_chsetneeds to beutf-8.gtm_icu_versionneeds to be set to the correct version of libicu. If you have libicu-dev, this is just a call toicu-config --version.- If importing from .zwr globals, modify them to add "UTF-8" on the first line
- Convert .zwr globals and .m routines from iso8859-1 encoding (how they are actually stored in VistA) to UTF-8 encoding. The
recodeoriconvcommands are good for doing that. If you use an existing M database and just decide that it will be UTF-8 for now, be aware that you may crash on some invalid data in random places in VistA.
The rest of the process is the normal process for creating a VistA instance.
CPRS Read/Write to VistA in UTF-8
Briefly, what we had to do in the Broker is to rewrite wsockc.pas. This was actually rather difficult, as it required good Object Pascal knowledge, which wasn't my forte. Since all strings were in UTF-16 in Object Pascal, we had to convert them to UTF-8 prior to being sent to VistA; and when we received from VistA, we converted from UTF-8 to UTF-16 encoding. On the VistA side, the changes were actually more limited: we only needed to change $L and $E to $ZL and $ZE. There were some other minor changes that had to do with ensuring that the broker know it had to operate in "M" mode rather than in UTF-8 mode, as the strings coming from the broker were not completely in UTF-8 yet (e.g. they may be broken over multiple lines).
There were two other Delphi side changes
- The Intro Text Rich Text Box was a custom component (to support URLs); but the custom component was ASCII only. The URL capability got taken out in the latest version of the broker; so in the end we just discarded the custom component and used the component that came with Delphi.
- There is a bug in
ConvertSidToStringA(a Win32 function) in the Korean Locale, where it gives us garbage even though the SID is Alpha-numeric and is fully representable in ASCII. Switching toConvertSidtoStringWfixes this problem.
With these changes, CPRS and any other Delphi Applications that include our changes will be able to read and write UTF-8 to VistA.
This is described in far more detail here, or dupliciated here.
Reports and TIU Unicode Support
Reports displayed non-ASCII data saved into VistA as ???. This was easily fixed; it was simply a Delphi procedure that needed to take an extra parameter.
TIU notes pasting and saving text was "cleaned up" with filters that removed non-ASCII characters. This was done to prevent saving non-ASCII data to VistA; since VistA now can take everything under the sun, we simply removed the filter.
The last problem was that were was M side code that checked for the presence of ASCII as a proxy for the note not being empty. That means if you wrote a note with non-ASCII text with no spaces, it was considered "empty" and was deleted. That was easy to fix.
This is described in more detail here, or duplicated here.
CPRS Localization Strategy and Framework
At this point, we can send and receive data fully in UTF-8; but all the labels in the program are still in English. Our first "port of call" was to check the official translation framework provided by Delphi: The Integrated Translation Environment (ITE). It had a large amount of problems--we actually couldn't use it even if we wanted to due to these issues. In the end we looked at multiple open source projects, and we chose "Kryvich's Localizer" because it's interoperable with ITE; it required very limited source code changes to get it working; and it had a very simple output format. We had human translators translate the output file containing the hardcoded strings into Korean and Chinese. We also created machine translations for French, Italian, Russian, and Arabic.
This is described in more detail here and here; or alternately duplicated here and here. The actual mechanics of choosing a language at runtime is described here.
CPRS Problem List Editing Issue
Delphi and VistA use ASCII 255 as a delimiter when editing a problem in the problem list. ASCII 255 is not valid UTF-8, and would crash VistA. We replaced ASCII 255 with a pipe ('|').
CPRS Date Formatting Issues
This was actually somewhat difficult, as there is no consistency in CPRS date formats. What we observed was that CPRS tended to follow VistA conventions for date formats rather than Windows conventions; and there was significant variability on whether CPRS includes time with seconds or not, plus a significant amount of time where human readable dates were sent to VistA as is for validation rather than sending a Fileman date. The Problem List and Vitals packages were two big culprits in that regard.
The VistA side framework for representing dates was easy to fix. On the CPRS side, to retain backwards compatibility, dates used the original formats for the US locale, and the Windows short date format for the other locales.
Due to the fact that CPRS sends human readable dates to VistA, VistA has to be able to parse these dates back. That essentially means that we have to reproduce the formatting of the Windows short date format in VistA.
There is a lot of VistA code which did its own date formatting. Each of these places needed to be fixed individually.
This is described in more detail with lots of screenshots here and duplicated here.
CPRS & Comma Decimals
This part of the project actually happened later than the other CPRS issues we had to fix -- almost 8 months later, while we were working on German with CPRS.
CPRS crashes when run in any MS Windows Locale that uses comma instead of dots as the decimal separator. This includes the Windows Locales for French, German, Italian, Russian and all Scandinavian Languages. The cause of the issue has to do with Floating Point conversion to/from strings. The Floating Point conversion fails because M always sends number to CPRS with dots as the decimal separator; whereas in all of these locales, a comma is the decimal separator.
We leave untouched the issue of displaying the decimal numbers on the M side, as there is no easy solution. I asked a person in Germany (Dr. W. Giere) who was previously involved with the implementation there of parts of VistA in the 1990s about that issue. His reply was that people actually lived with the foreign decimal point, unless the data needed to imported into an external program, such as Excel.
This is described in more detail here, and duplicated here.
Ability to enter CJK names
VistA as is could only accommodate ASCII names. One big problem in trying to enter Chinese, Japanese, and Korean (CJK) names was that VistA code checked that the name was uppercase; and if not, tried to uppercase it. Case in language does not exist outside of European languages written in Roman, Cyrillic, or Greek scripts. The first change to allow CJK languages was to only check case if the language supports case.
With the above change, we can enter longer CJK names (as in 2 characters or longer). However, many CJK names are only a single character long. So the other change that was needed was to allow a family name or a given name that is one character long.
Later, we tested these changes with Cyrillic and Arabic scripts. They proved adequate and no further changes were needed to be made.
These were all the changes we made. These changes do not address the following issues:
- The sorting is done by the M database. We have no control over this; if the UTF-8 sorting is inappropriate for the culture, the M database gives you control to allow you to implement a custom sorting module. I unfortunately couldn't tell if the sorting in Korean is correct or not.
- East Asian cultures typically express names as "FAMILY GIVEN". In VistA, the format is "FAMILY,GIVEN MIDDLE". They are close.
More details (including the specific changed routines) are here.
Fileman Data Localization
Fileman has mechanisms to localize date/time displays, number formatting, all the user dialogs that Fileman is responsible for, and the data dictionary. One thing it does not allow to localize though is data. Normally, you would assume that files are "empty" and then you would fill them with entries in your own language. However, many files have reference data that needs to be translated. For example, CPRS Cover Sheet & CPRS Reports have definitions that include their header names stored in file OE/RR Report (#101.24). Ultimately, this turned out to be a hard problem to solve. We came up with a single solution: Non-indexed data can be localized using the dialog framework. There is no way to localize indexed data (data that needs to be searched) without extensive changes to Fileman which this project was not prepared to undertake. The only solution is to replace the indexed data with the other language's strings. This is problematic as this won't work for more than one language at a time. We did this for the menu system, as described below.
More details on the full implementation of data localization are here.
HL7 Send/Receive Support
Actually, there were no changes that were needed due to internationalization. As a bonus, outside of this project, I wrote a how-to guide to get HL7 going on VistA:.
Menu System
As alluded to in the section on Fileman Data Localization, the menu system consists of indexed data; actually not just indexed, but cached too. Theoretically speaking, the indexes and cache creation code can be modified to check a new data point that changes based on language; but in the end I decided this was too much work to do in the time given for the project. Instead, we translated the user visible text for menus by moving the entries into the dialog file. To switch languages, you have to copy the translations (or restore the original English) from the dialog file.
In addition to translating the data, the menu system driver in "XQ*" needed to be translated as well. An interesting issue came up translating some of the hardcoded strings in the XQ* routines, such as "Select {string} option". These were done in the code by concatenating the string. This does not work well for translation -- other languages will not have the same order of words as English. In these cases, concatenated strings need to be converted to phrases, which are internationalized all together as a unit.
We also needed to translate various Fileman pre-existing dialogs used in the menu system--mostly the ones involved in answering Yes/No questions. Later during this project I discover that translating these and making Fileman use them broke Patient Registration. There was a small bug in Fileman that needed to be fixed.
More details can be found in two slide sets: Part 1 and Part 2. The latter slides (which are the most comprehensive) can also be found on OSEHRA's website here.
CJK Wide Character Issues
This was not an obvious issue except in the Fileman Screen Editor (a word processing field editor); it took me a few weeks to exactly understand the issue. Chinese, Japanese, and Korean characters take up two (2) spaces in VT-100+ terminal emulated applications. Screen oriented VistA applications always assume a single character is one space wide.
This was a pervasive issue in multiple VistA applications, with no easy fix on the VistA side. The most common manifestation of this issue is seeing text that is supposed to be 80 characters long scroll off the screen and anything that is supposed to line up not line up (see the screenshot below):
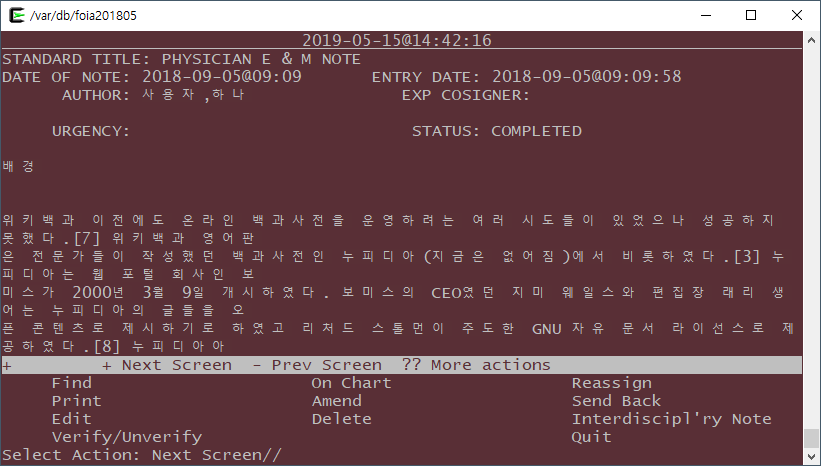
In Screenman and the Screen-oriented editor, editing any text that contains CJK characters is difficult as the character positioning assumptions are wrong. Both programs need to be fixed, but there was not enough time in the schedule to do that. The screen-oriented editor can be easily replaced with a call out to a program such as "nano" which knows how to handle wide characters correctly.
Sample Application Translation
This part of the project was started; but since adding the Korean ICD-10 was added to the schedule and was expected to take a long time, doing a Sample Application Translation was never fully completed. One interesting output of the short time I spent is the routine UKOP6TRA. This routine moves the hardcoded strings out of a routine and into the dialog file. There is bonus code there as well to XINDEX the new routine--I did that as a way to check that the new routine I constructed is syntactically correct.
Lexicon Update
We had a request to put the Korean ICD-10 system into the Lexicon; this was not originally on the project schedule, but ultimately we decided to pursue this over doing a Sample Application Translation. After a false start (I assumed that the Korean ICD-10 will have the same codes as the US version; which was very far from being the case); I ended up replacing the US ICD-10 with the Korean version. In a perfect world, the coding systems will be universal and the same codes can be used across countries. Unfortunately, that is not the case.
Updating the Lexicon involved a significant learning curve.
More detail in this blog post. Modifying the Lexicon was not done for any other country coding system.
DataLoader
The Dataloader is a C# application written for VistA for Education that let you import data in Excel spreadsheets. It relied on a little known dll that is part of the broker called "bapi32.dll". As you may remember from earlier in this document, we changed the broker Delphi source code to ensure that the broker worked with non-ASCII languages. We therefore needed to recompile bapi32.dll to ensure that it uses the new code. Finding the source code for bapi32.dll was difficult--but eventually we found it. After compilation it turned out that we needed to modify the C# interface to bapi32.dll as well to pass Unicode rather than ASCII strings (BapiHelper.cs in VistA.DataLoader.Broker project).
The VistA DataLoader source and install instructions can be found on Github.
The Plan VI presentation can be found here or duplicated here.
QEWD and Panorama
We did not plan to spend much time in the project on using Panorama, as it does not provide as of today any production ready VistA interfaces. However, we were pleasantly surprised that it just works out of the box.
Project Outputs
Documentation and Presentations
This blog post and everything linked from it, plus everything on the VistA Internationlization Project Group functions as good documentation on what was done. For ease of reference, I have all the important presentations/blog posts in chronological order on My Website. Instructions to help you implement CPRS in your own language are here.
KIDS Build
All the M code changes to VistA that will apply to any internationalization effort are packaged in a single KIDS build, which can be downloaded from here.
CPRS Executable & Vitals DLL
All the work on CPRS (and some work on the Vitals DLL to fix the date issues) can be found ready to run here. This release is designed to work on any Windows locale. CPRS Picks Language dynamically based on User Locale. We also supply translations files for Korean and Chinese (Human translations) and German, Italian, Russian and Arabic (Machine). Instructions to create a new translation can be found here.
Docker Images
We have two ready to use Docker Images: OSEHRA VistA 6, which contains limited demo data and is thus suitable as a starting point for a database to be used in production. VEHU VistA 6 is a database full of demo data.
There is no need to install the KIDS build into VistA as all the modified code and data are already integrated. The docker images also contain the Korean ICD-10 instead of the US version.
Do note that the docker images are configured for Korean.
This link has a couple of screenshots for the OSEHRA VistA 6 docker image.
Github Repositories
There are two main Github repositories:
- OSEHRA-Sandbox/VistA, plan-vi branch, which contains the source code for CPRS and the Vitals Packages; plus, it contains the source reStructuredText for this document and all other blog posts.
- OSEHRA-Sandbox/VistA-M, plan-vi branch, which contains all the M side changes (routines and rare global updates). All the M changes are continuously rebased on the latest OSEHRA VistA. As of the time of this writing, they are rebased on OSEHRA VistA's February 2019 release. Since the project started, we rebased our changes twice.
In addition, there is an plan-vi branch on the OSEHRA-Sandbox/VistA-VEHU-M which takes commits from the OSEHRA-Sandbox/VistA-M repo and applies them over a VEHU instance in order to apply the changes made in VistA-M to a VistA VEHU instance. This is done using git format-patch ... | git am.
Testing Script
Originally we were going to have Sikuli testing framework to test the changes that were made to CPRS. However, Sikuli looks at images not content; and having it analyze and correctly decide that (for example) a date string looks correct for a specific locale is not something that it can do. We haven't quite decided yet what is the best way to do automated checking. I came up with this manual check list of things to check to ensure that all of our code works once you set the Kernel Language to Korean:
Roll & Scroll
- Access/Verify Code prompt in Korean
- Menu prompts are in Korean
- Able to Register a Patient with name in English
- Able to Register a Patient with name in Korean
CPRS
- Patient Selection DOB format appropriate
- Notification date format is culturally appropriate
- The various static screen elements are in Korean
- Cover Sheet headers are in Korean
- Encounter Date selection has correct drop down box for dates (Korean weekdays for example)
- Encounter Date box will show the correct date format before and after selection
- Able to enter and graph vitals using the Vitals DLL. The graph dates are culturally correct.
- Vitals display in the coversheet is correct
- Create a new note. Paste a few characters of Korean in with no spaces. Make sure that the note actually saves. Saved note should have multiple dates showing on the screen. Make sure all of them are culturally appropriate.
- Create a generic order (e.g. Diagnosis; Movement; etc) with some Korean text; sign; and then view the order details (e.g. by double clicking). Make sure that the Korean text shows up in the Order Details
- Create Problem and save. Annotate the problem with Korean Text. Edit some of the problem details and save. Enter an inexact onset date in Korean format (e.g. 2011/05). Save. Double click to view problem details.
- Go to Tools > Options > Reports and change the start/stop dates for reports; and save. Signout of CPRS and signin again, and make sure the new dates are still there.
- Go to the reports tab and try various reports, with few rare exceptions, most reports should show the correct date format.
- Only if the Lexicon KIDS build is installed: In the Encounter button, go to Diagnosis, and test searching for Asthma in Korean (천식). Test searching for Asthma in English and seeing a Korean code. Test searching for "J00" and getting a result back.
DataLoader
- Should be able to create a patient whose name is in Korean